# Jekyll Search
# Entrega
La entrega de esta práctica se realizará en el mismo repo asociado a la práctica Introduction to Systems Development.
Cree una rama intro2sd para señalar el punto de entrega de la anterior y haga la entrega de esta tarea en la rama main.
# Adding a Simple Search to our Jekyll Site
El ejercicio consiste en que añada la capacidad de búsqueda al sitio web contruido en la práctica Introduction to Systems Development
Estos son algunos requisitos:
- Queremos que busque en todos los ficheros, no solo los de los posts sino también los de las páginas
- Que admita expresiones regulares
- Queremos que los resultados vayan apareciendo conforme tecleamos
- Se mostrará una lista de enlaces a los ficheros que contienen la expresión buscada y un resumen de las primeros caracteres del fichero
- Lea el capítulo 2 del libro Developing Information Systems, editado by James Cadle y haga un resumen en un post del web site
- Capítulo 2: Lifecycle types and their rationales (opens new window) por Lynda Girvan
Véase un ejemplo en funcionamiento en ull-mfp-aet.github.io/search/ (opens new window).
# ¿Como hacerlo?
Since Jekyll has no server side execution, we have to rely on storing all the required content in a single file and search our keyword from that file.
We will be creating a JSON file in which we will store
title,url,content,excerpt, etc., at building time$ bundle exec jekyll build $ head -n 30 _site/assets/src/search.json1
2[ { "title": "Clase del Lunes 30/09/2019", "excerpt": "Clase del Lunes 30/09/2019\n\n", "⇐": " Resumen", "content": "Clase del Lunes 30/09/2019\n\n\n ...", "⇐ ": "Contenido del fichero" "url": "/clases/2019/09/30/leccion.html" }, "...": "..." ]1
2
3
4
5
6
7
8
9
Véase search.json (opens new window) (protected)
# Liquid template to generate at build time the _site/assets/src/search.json
In your case it is convenient to have this file in the pages
---
layout: null
sitemap: false
---
{% capture json %}
[
{% assign collections = site.collections | where_exp:'collection','collection.output != false' %}
{% for collection in collections %}
{% assign docs = collection.docs | where_exp:'doc','doc.sitemap != false' %}
{% for doc in docs %}
{
"title": {{ doc.title | jsonify }},
"excerpt": {{ doc.excerpt | markdownify | strip_html | jsonify }},
"content": {{ doc.content | markdownify | strip_html | jsonify }},
"url": {{ site.baseurl | append: doc.url | jsonify }}
},
{% endfor %}
{% endfor %}
{% assign pages = site.html_pages | where_exp:'doc','doc.sitemap != false' | where_exp:'doc','doc.title != null' %}
{% for page in pages %}
{
"title": {{ page.title | jsonify }},
"excerpt": {{ page.excerpt | markdownify | strip_html | jsonify }},
"content": {{ page.content | markdownify | strip_html | jsonify }},
"url": {{ site.baseurl | append: page.url | jsonify }}
}{% unless forloop.last %},{% endunless %}
{% endfor %}
]
{% endcapture %}
{{ json | lstrip }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
You can find the
source code at /ULL-MFP-AET/ull-mfp-aet.github.io/main/assets/src/search.json
layout: null: To disable layout in Jekyll.sitemap: false:- A Sitemap is an XML file that lists the URLs for a site. This allows search engines to crawl the site more efficiently and to find URLs that may be isolated from rest of the site's content. The sitemaps protocol is a URL inclusion protocol
and complements robots.txt, a URL exclusion protocol. We can use the front-matter to set thesitemapproperty tofalse - jekyll-sitemap
is a Jekyll plugin to silently generate a sitemaps.org compliant sitemap for your Jekyll site
- A Sitemap is an XML file that lists the URLs for a site. This allows search engines to crawl the site more efficiently and to find URLs that may be isolated from rest of the site's content. The sitemaps protocol is a URL inclusion protocol
- Liquid:
{% capture json %} ... {% endcapture %}Captures the string inside of the opening and closing tags and assigns it to a variable. Variables that you create using capture are stored as strings. {{ json | lstrip }}:- Filters are simple methods that modify the output of numbers, strings, variables and objects. They are placed within an output tag
{{ }}and are denoted by a pipe character|. - lstrip: Removes all whitespace (tabs, spaces, and newlines) from the left side of a string. It does not affect spaces between words.
- Filters are simple methods that modify the output of numbers, strings, variables and objects. They are placed within an output tag
{% assign collections = site.collections ...site.collections: Collections are also available undersite.collections. Posts are considered a collections by Jekyll.- ...
where_exp:'collection','collection.output != false'site.collectionsis an array. Withwhere_expwe select all the objects in the array with the elements for which the attributecollectionhas itsoutputattribute totrue.- The
outputattribute of a collection controls whether the collection's documents will be output as individual files.
- iteration in Liquid
site.html_pages: A subset ofsite.pageslisting those which end in.html.
Use the Liquid Playground
# Entendiendo la línea `"content": {{ page.content | markdownify | strip_html | jsonify }}
page.contentel contenido de la página todavia sin renderizar (se supone que es fundamentalmente markdown, pero puede contener yml en el front-matter, html, scripts, liquid, etc.)markdownify: Convert a Markdown-formatted string into HTML.- strip_html
: Removes any HTML tags from a string. jsonify: If the data is an array or hash you can use the jsonify filter to convert it to JSON.
TIP
La idea general es que necesitamos suprimir los tags, tanto yml, markdown, HTML, etc. para que no confundan al método de busca. Por eso convertimos el markdown a HTML y después suprimimos los tags HTML. También convertimos el yml a JSON.
# La página de Búsqueda: search.md
Fuente: search.md (opens new window)
La idea es que vamos a escribir una clase JekyllSearch que implementa la búsqueda.
Debe disponer de un constructor al que se le pasan cuatro argumentos:
const search = new JekyllSearch(
'/assets/src/search.json',
'#search',
'#list',
'' // put here your baseurl
);
search.init();
2
3
4
5
6
7
- La ruta donde esta disponible el fichero .json generado durante la construcción (
jekyll build) - El
iddel objeto del DOM en la página en la que está el taginputde la búsqueda - El
iddel objeto del DOM en el que se deben volcar los resultados - La
urldel lugar en el que está el deployment (pudiera ser que el site en el que queremos buscar fuera una subcarpeta de todo el site)
Los objetos JekyllSearch deben disponer de un método init que realiza la búsqueda especificada en el elemento del DOM #search y añade los resultados en en el elemento del DOM #list
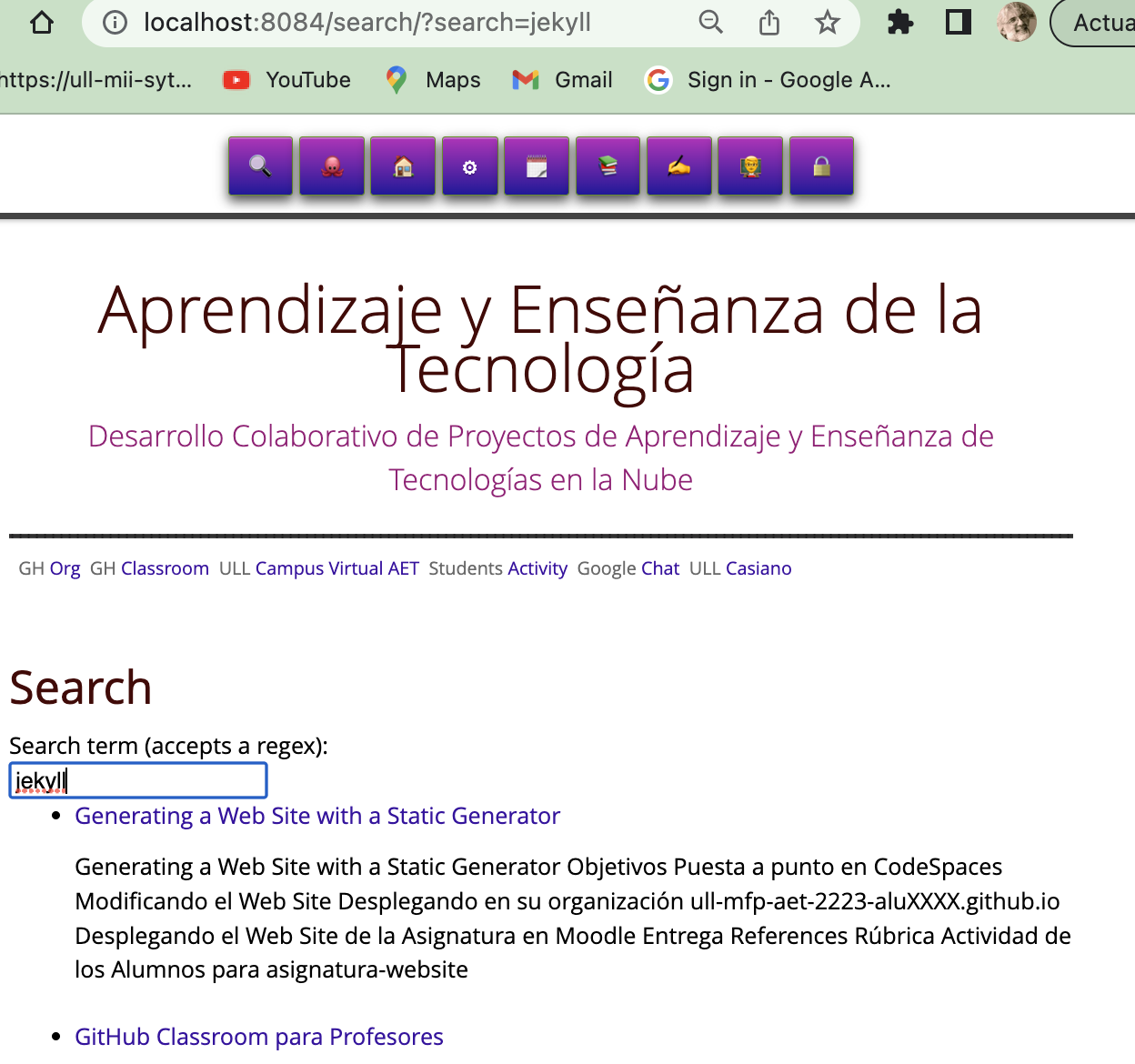
---
layout: error
permalink: /search/
title: Search
---
{% capture initSearch %}
<h1>Search</h1>
<form id="search-form" action="">
<label class="label" for="search">Search term (accepts a regex):</label>
<br/>
<input class="input" id="search" type="text" name="search"
autofocus
placeholder="e.g. Promise"
autocomplete="off">
<ul class="list list--results" id="list">
</ul>
</form>
< script type="text/javascript" src="/assets/src/fetch.js"></script>
< script type="text/javascript" src="/assets/src/search.js"></script>
< script type="text/javascript">
const search = new JekyllSearch(
'{{site.url}}/assets/src/search.json',
'#search',
'#list',
'' // put here your /baseurl/
);
search.init();
</script>
<noscript>Please enable JavaScript to use the search form.</noscript>
{% endcapture %}
{{ initSearch | lstrip }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
autocomplete="off"- En algunos casos, el navegador continuará sugiriendo valores de autocompletado incluso si el atributo autocompletar está desactivado. Este comportamiento inesperado puede resultar bastante confuso para los desarrolladores. El truco para realmente no aplicar el autocompletado es asignar un valor no válido al atributo, por ejemplo,
autocomplete="nope". Dado que este valor no es válido para el atributo autocompletar, el navegador no tiene forma de reconocerlo y deja de intentar autocompletarlo.
- En algunos casos, el navegador continuará sugiriendo valores de autocompletado incluso si el atributo autocompletar está desactivado. Este comportamiento inesperado puede resultar bastante confuso para los desarrolladores. El truco para realmente no aplicar el autocompletado es asignar un valor no válido al atributo, por ejemplo,
Filters are simple methods that modify the output of numbers, strings, variables and objects. They are placed within an output tag
{{ }}and are denoted by a pipe character|.Clearing Up Confusion Around baseurl
. About site.urlvssite.baseurl

# La clase JekyllSearch: Fichero search.js
You can find the source at ULL-MFP-AET/ull-mfp-aet.github.io/assets/src/search.js (opens new window)
Here are the contents:
class JekyllSearch {
constructor(dataSource, searchField, resultsList, siteURL) {
this.dataSource = dataSource
this.searchField = document.querySelector(searchField)
this.resultsList = document.querySelector(resultsList)
this.siteURL = siteURL
this.data = [];
}
fetchedData() {
return fetch(this.dataSource, {mode: 'no-cors'})
.then(blob => blob.json())
}
async findResults() {
this.data = await this.fetchedData()
const regex = new RegExp(this.searchField.value, 'i')
return this.data.filter(item => {
return item.title.match(regex) || item.content.match(regex)
})
}
async displayResults() {
const results = await this.findResults()
//console.log('this.siteURL = ',this.siteURL)
const html = results.map(item => {
//console.log(item)
return `
<li class="result">
<article class="result__article article">
<h4>
<a href="${item.url}">${item.title}</a>
</h4>
<p>${item.excerpt}</p>
</article>
</li>`
}).join('')
if ((results.length == 0) || (this.searchField.value == '')) {
this.resultsList.innerHTML = `<p>Sorry, nothing was found</p>`
} else {
this.resultsList.innerHTML = html
}
}
// https://stackoverflow.com/questions/43431550/async-await-class-constructor
init() {
const url = new URL(document.location)
if (url.searchParams.get("search")) {
this.searchField.value = url.searchParams.get("search")
this.displayResults()
}
this.searchField.addEventListener('keyup', () => {
this.displayResults()
// So that when going back in the browser we keep the search
url.searchParams.set("search", this.searchField.value)
window.history.pushState('', '', url.href)
})
// to not send the form each time <enter> is pressed
this.searchField.addEventListener('keypress', event => {
if (event.keyCode == 13) {
event.preventDefault()
}
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# constructor
constructor(dataSource, searchField, resultsList, siteURL) {
this.dataSource = dataSource
this.searchField = document.querySelector(searchField)
this.resultsList = document.querySelector(resultsList)
this.siteURL = siteURL
this.data = [];
}
2
3
4
5
6
7
8
The Document method querySelectorAll() (opens new window)
returns a static (not live) NodeList representing a list of the
document's elements that match the specified group of selectors.
selectors: In CSS, pattern matching rules determine which style rules apply to elements in the document tree. These patterns, are called selectors, may range from simple element names to rich contextual patterns. If all conditions in the pattern are true for a certain element, the selector matches the element. For instance '#search' and '#list' are selectors.
All methods getElementsBy* return a live collection (opens new window).
Such collections always reflect the current state of the document and auto-update when it changes.
In contrast, querySelectorAll returns a static collection.
It’s like a fixed array of elements.
# init
init() {
const url = new URL(document.location)
if (url.searchParams.get("search")) {
this.searchField.value = url.searchParams.get("search")
this.displayResults()
}
this.searchField.addEventListener('keyup', () => {
this.displayResults()
// So that when going back in the browser we keep the search
url.searchParams.set("search", this.searchField.value)
window.history.pushState('', '', url.href)
})
// to not send the form each time <enter> is pressed
this.searchField.addEventListener('keypress', event => {
if (event.keyCode == 13) {
event.preventDefault()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# URL parameters
(also known as query strings) are a way to structure additional information for a given URL.
Parameters are added to the end of a URL after a ? symbol, and multiple parameters can be included when separated by the & symbol.

In our case, we have the search parameter:
# url.searchParams
If the URL of your page is https://example.com/?name=Jonathan%20Smith&age=18 you could parse out the name and age parameters using:
let params = (new URL(document.location)).searchParams;
let name = params.get('name'); // is the string "Jonathan Smith".
let age = parseInt(params.get('age')); // is the number 18
2
3
# The event listeners
this.searchField.addEventListener('keyup', () => {
this.displayResults()
// So that when going back in the browser we keep the search
url.searchParams.set("search", this.searchField.value)
window.history.pushState('', '', url.href)
})
2
3
4
5
6
# window.history.pushState
The window object provides access to the browser's session history through the history object.
The history.pushState(state, title, url) method adds a state to the browser's session history stack.
... // inside init
this.searchField.addEventListener('keyup', () => {
this.displayResults()
// So that when going back in the browser we keep the search
url.searchParams.set("search", this.searchField.value)
window.history.pushState('', '', url.href)
})
2
3
4
5
6
7
The search.json is not going to change until the next push
# findResults
fetchedData() {
return fetch(this.dataSource, {mode: 'no-cors'})
.then(blob => blob.json())
}
async findResults() {
this.data = await this.fetchedData()
const regex = new RegExp(this.searchField.value, 'i')
return this.data.filter(item => {
return item.title.match(regex) || item.content.match(regex)
})
}
2
3
4
5
6
7
8
9
10
11
12
# What is CORS
The mode option of the fetch() method allows you to define the CORS mode (opens new window) of the request:
no-corsprevents the method from being anything other thanHEAD,GETorPOST, and the headers from being anything other than simple headers.- If any ServiceWorkers intercept these requests, they may not add or override any headers except for those that are simple headers. See section Service Workers for more information.
- In addition,
no-corsassures that JavaScript may not access any properties of the resultingResponse.- This ensures that ServiceWorkers do not affect the semantics of the Web and prevents security and privacy issues arising from leaking data across domains.
# Caching
The resources downloaded through fetch(), similar to other resources that the browser downloads, are subject to the HTTP cache (opens new window).
fetchedData() {
return fetch(this.dataSource).then(blob => blob.json())
}
2
3
This is usually fine, since it means that if your browser has a cached copy of the response to the HTTP request, it can use the cached copy instead of wasting time and bandwidth re-downloading from a remote server.
# Fetch Polyfill
- El código del polyfill que he usado: assets/src/fetch.js (opens new window)
- Para mas información podemos leer este blog: Polyfill para Fetch (opens new window)
- whatwg-fetch: polyfill de Fetch que ha creado el equipo de Github (opens new window)
- Para agregar este polyfill a nuestro proyecto podemos descargarnos su archivo js desde github,
- pero también podríamos instalarlo usando cualquiera de los gestores de dependencias más habituales:
npm install whatwg-fetch --save- o bien:
bower install fetch --save
# Estructura del sitio
Esta imagen muestra los ficheros implicados en este ejercicio dentro de la estructura del sitio de estos apuntes:
$ tree -I _site
.
├── 404.md
├── assets
│ ├── css
│ │ └── style.scss
│ ├── images
│ │ ├── event-emitter-methods.png
│ │ └── ,,,
│ └── src
│ ├── fetch.js ⇐ Polyfill for fetch
│ ├── search.js ⇐ Librería con la Clase JekyllSearch que implementa el Código de búsqueda
│ └── search.json ⇐ Plantilla Liquid para generar el fichero JSON
├── search.md ⇐ Página de la búsqueda. Formulario y script de arranque
├── clases.md
├── _config.yml ⇐ Fichero de configuración de Jekyll
├── degree.md
├── favicon.ico
├── Gemfile
├── Gemfile.lock
├── _includes ⇐ The include tag allows to include the content of files stored here
│ ├── navigation-bar.html
│ └── ...
├── _layouts ⇐ templates that wrap around your content
│ ├── default.html
│ ├── error.html
│ └── post.html
├── _posts ⇐ File names must follow YEAR-MONTH-DAY-title.MARKUP and must begin with front matter
│ ├── ...
│ └── 2019-12-02-leccion.md
├── _practicas ⇐ Folder for the collection "practicas" (list of published "practicas")
│ ├── ...
│ └── p9-t3-transfoming-data.md
├── practicas.md ⇐ {% for practica in site.practicas %} ... {% endfor %}
├── Rakefile ⇐ For tasks
├── README.md
├── references.md
├── resources.md
├── tema0-presentacion ⇐ Pages folders
│ ├── README.md
│ └── ...
├── tema ...
├── tfa
│ └── README.md
└── timetables.md
58 directories, 219 files
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# Referencias
- Sección Jekyll en estos apuntes
- Liquid Playground (opens new window)
- Liquid (opens new window)
- Jekyll Liquid Extensions (opens new window)
- Using HTMLProofer From Ruby and Travis (opens new window). Para testear tus páginas: links, imágenes, etc.